
![]() eBook
eBook
The 2024 CE Pro Playbook
Download Now
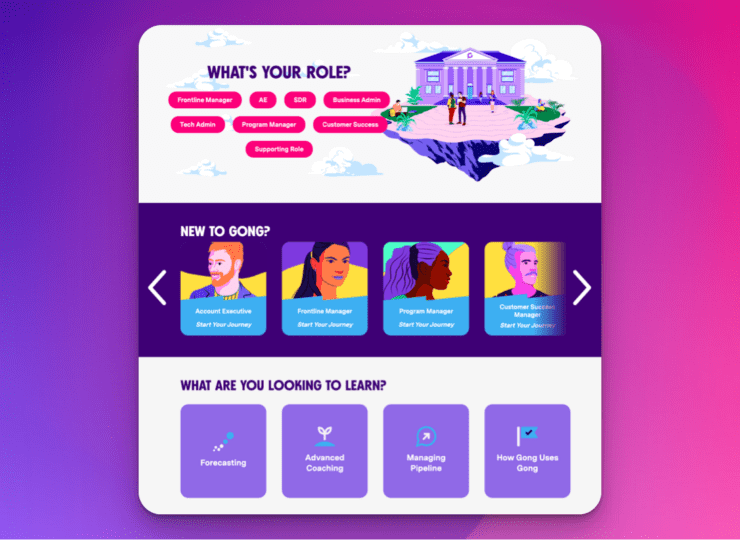
Transform education from cost center to strategic asset. Tie customer training to business impact, like product adoption, lower support costs, and retention.

Know Customer Education’s real business value using our tools, analytics, and data to tie adoption to retention and expansion.
Lean on your Academy to educate customers on their terms and reserve your CSMs for only the most strategic conversations.
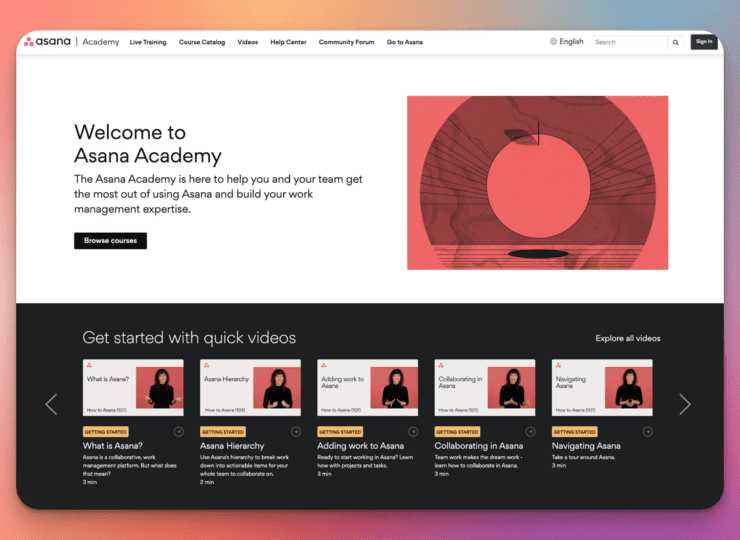
Designed for external learners, Skilljar elevates your Academy, making it a pivotal touchpoint in your customer journey.



G2: Category Leader, Customer Education

TrustRadius: Top Rated, Best Feature Set, Customer Training
APPEALIE: SaaS Customer Success Award Winner, Overall SaaS Award Winner in HR + Learning

Inc. 5000: Fastest-Growing Private Companies in America

Deloitte Technology Fast 500 Award Winner

GeekWire: UX Design of the Year

2020 Top Learning Portal/LMS Companies Watch List

2022 Talented Learning Best Learning Systems Awards: Corporate Extended Enterprise
G2: Category Leader, Customer Education
TrustRadius: Top Rated, Best Feature Set, Customer Training
APPEALIE: SaaS Customer Success Award Winner, Overall SaaS Award Winner in HR + Learning
Inc. 5000: Fastest-Growing Private Companies in America
Deloitte Technology Fast 500 Award Winner
GeekWire: UX Design of the Year
2020 Top Learning Portal/LMS Companies Watch List
2022 Talented Learning Best Learning Systems Awards: Corporate Extended Enterprise

"Amazingly versatile. Helping us scale to thousands of students. More than anything, the Skilljar onboarding team is incredible - they set us up for success and proactively checked in with us for months, giving us constant advice on how to better our student experience."